kubernetes监控Prometheus
原先版本是用heapster来收集资源指标才能看,但是现在heapster要废弃了。
从k8s v1.8开始后,引入了新的功能,即把资源指标引入api;
在使用heapster时,获取资源指标是由heapster自已获取的,heapster有自已的获取路径,没有通过apiserver,后来k8s引入了资源指标API(Metrics API),于是资源指标的数据就从k8s的api中的直接获取,不必再通过其它途径。
metrics-server: 它也是一种API Server,提供了核心的Metrics API,就像k8s组件kube-apiserver提供了很多API群组一样,但它不是k8s组成部分,而是托管运行在k8s之上的Pod。
为了让用户无缝的使用metrics-server当中的API,还需要把这类自定义的API,通过聚合器聚合到核心API组里,
然后可以把此API当作是核心API的一部分,通过kubectl api-versions可直接查看。
metrics-server收集指标数据的方式是从各节点上kubelet提供的Summary API 即10250端口收集数据,收集Node和Pod核心资源指标数据,主要是内存和cpu方面的使用情况,并将收集的信息存储在内存中,所以当通过kubectl top不能查看资源数据的历史情况,其它资源指标数据则通过prometheus采集了。
k8s中很多组件是依赖于资源指标API的功能 ,比如kubectl top 、hpa,如果没有一个资源指标API接口,这些组件是没法运行的;
资源指标:metrics-server
自定义指标: prometheus, k8s-prometheus-adapter
新一代架构:
- 核心指标流水线:由kubelet、metrics-server以及由API server提供的api组成;cpu累计利用率、内存实时利用率、pod的资源占用率及容器的磁盘占用率;
- 监控流水线:用于从系统收集各种指标数据并提供终端用户、存储系统以及HPA,他们包含核心指标以及许多非核心指标。非核心指标不能被k8s所解析;
metrics-server是一个api server,收集cpu利用率、内存利用率等
1. metrics-server
需要修改的地方
vim resource-reader.yaml
...
...
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- namespaces
- nodes/stats #添加此行
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- deployments
...
...vim metrics-server-deployment.yaml
...
...
containers:
- name: metrics-server
image: ccr.ccs.tencentyun.com/cl0411/metrics-server-amd64:v0.3.1 #修改镜像
command:
- /metrics-server
- --metric-resolution=30s
- --kubelet-insecure-tls ##添加此行
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP #添加此行
# These are needed for GKE, which doesn't support secure communication yet.
# Remove these lines for non-GKE clusters, and when GKE supports token-based auth.
#- --kubelet-port=10255
#- --deprecated-kubelet-completely-insecure=true
ports:
- containerPort: 443
name: https
protocol: TCP
- name: metrics-server-nanny
image: ccr.ccs.tencentyun.com/cl0411/addon-resizer:1.8.4 #修改镜像
resources:
limits:
cpu: 100m
memory: 300Mi
requests:
cpu: 5m
memory: 50Mi
...
...
# 修改containers,metrics-server-nanny 启动参数,修改好的如下:
volumeMounts:
- name: metrics-server-config-volume
mountPath: /etc/config
command:
- /pod_nanny
- --config-dir=/etc/config
- --cpu=80m
- --extra-cpu=0.5m
- --memory=80Mi
- --extra-memory=8Mi
- --threshold=5
- --deployment=metrics-server-v0.3.1
- --container=metrics-server
- --poll-period=300000
- --estimator=exponential
# Specifies the smallest cluster (defined in number of nodes)
# resources will be scaled to.
- --minClusterSize=2
...
...绑定角色
[root@node1 metrics-server]# kubectl create clusterrolebinding system:kube-proxy --clusterrole=cluster-admin --user=system:kube-proxy
clusterrolebinding.rbac.authorization.k8s.io/system:kube-proxy created执行以下操作
kubectl apply -f ./
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
serviceaccount/metrics-server created
configmap/metrics-server-config created
deployment.apps/metrics-server-v0.3.1 created
service/metrics-server created获取node资源占用
[root@node1 metrics-server]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
192.168.57.13 128m 12% 1061Mi 76%
192.168.57.14 88m 8% 494Mi 35%
192.168.57.15 81m 8% 483Mi 34%获取pod资源占用
[root@node1 metrics-server]# kubectl top pod coredns-5fffdf46b6-49bh6 -n kube-system
NAME CPU(cores) MEMORY(bytes)
coredns-5fffdf46b6-49bh6 2m 17Mi二、prometheus
metrics只能监控cpu和内存,对于其他指标如用户自定义的监控指标,metrics就无法监控到了。这时就需要另外一个组件叫prometheus;
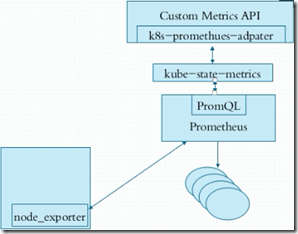
node_exporter是agent;
PromQL相当于sql语句来查询数据;
k8s-prometheus-adapter:prometheus是不能直接解析k8s的指标的,需要借助k8s-prometheus-adapter转换成api;
kube-state-metrics是用来整合数据的;
kubernetes中prometheus的项目地址:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/prometheus
马哥的prometheus项目地址:https://github.com/ikubernetes/k8s-prom
1、部署node_exporter
git clone https://github.com/iKubernetes/k8s-prom.git
[root@node1 ~]# cd k8s-prom/
[root@node1 k8s-prom]# ls
k8s-prometheus-adapter kube-state-metrics namespace.yaml node_exporter podinfo prometheus README.md
[root@node1 k8s-prom]# kubectl apply -f namespace.yaml
namespace/prom created
[root@node1 k8s-prom]# cd node_exporter/
[root@node1 node_exporter]# ls
node-exporter-ds.yaml node-exporter-svc.yaml
[root@node1 node_exporter]# kubectl apply -f .
daemonset.apps/prometheus-node-exporter created
service/prometheus-node-exporter created部署prometheus
[root@node1 node_exporter]# cd ../prometheus/
[root@node1 prometheus]# ls
prometheus-cfg.yaml prometheus-deploy.yaml prometheus-rbac.yaml prometheus-svc.yaml
[root@node1 prometheus]# vim prometheus-deploy.yaml prometheus-deploy.yaml文件中有限制使用内存的定义,如果内存不够用,可以将此规则删除;
[root@node1 prometheus]# kubectl apply -f ./
configmap/prometheus-config created
deployment.apps/prometheus-server created
clusterrole.rbac.authorization.k8s.io/prometheus created
serviceaccount/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
service/prometheus created打开查看http://192.168.57.14:30090/graph 这里的IP为任意节点地址
生产环境应该使用pv+pvc的方式部署;
部署kube-state-metrics
kube-state-metrics-deploy.yaml 镜像地址使用如下地址
ccr.ccs.tencentyun.com/cl0411/kube-state-metrics-amd64:v1.3.1
[root@node1 prometheus]# cd ../kube-state-metrics/
[root@node1 kube-state-metrics]# kubectl apply -f .
deployment.apps/kube-state-metrics created
serviceaccount/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
service/kube-state-metrics created
部署k8s-prometheus-adapter
[root@node1 ssl]# cat serving.json
{
"CN": "serving",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing"
}
]
}
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes serving.json | cfssljson -bare serving
kubectl create secret generic cm-adapter-serving-certs --from-file=serving.crt=./serving.pem --from-file=serving.key=./serving-key.pem -n prom
[root@node1 k8s-prom]# cd k8s-prometheus-adapter/
[root@node1 k8s-prometheus-adapter]# mv custom-metrics-apiserver-deployment.yaml {,.bak}
[root@node1 k8s-prometheus-adapter]# wget https://raw.githubusercontent.com/DirectXMan12/k8s-prometheus-adapter/master/deploy/manifests/custom-metrics-apiserver-deployment.yaml
[root@node1 k8s-prometheus-adapter]# wget https://raw.githubusercontent.com/DirectXMan12/k8s-prometheus-adapter/master/deploy/manifests/custom-metrics-config-map.yaml
#把两个文件里面的namespace的字段值改成prom
kubectl apply -f ./prometheus和grafana整合
wget https://raw.githubusercontent.com/kubernetes-retired/heapster/master/deploy/kube-config/influxdb/grafana.yaml
[root@node1 metrics]# vim grafana.yaml
第5行和第59行 namespace: prom 修改命名空间为prom
第60行开启 type: NodePort
镜像使用此地址 image: ccr.ccs.tencentyun.com/cl0411/heapster-grafana-amd64:v5.0.4
删除下面两行
#- name: INFLUXDB_HOST #注释此行
# value: monitoring-influxdb
kubectl apply -f grafana.yaml
以上通过以后,点击“Dashboards”,将三个模板都导入;
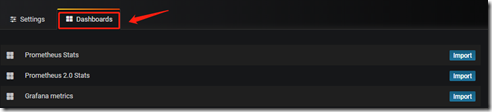
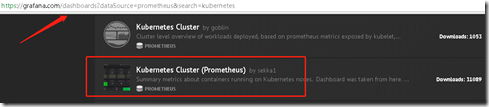
也可以去下载一些模板:
https://grafana.com/dashboards
https://grafana.com/dashboards?dataSource=prometheus&search=kubernetes

 cwit.com/uploads/2023/05/p5.png)
cwit.com/uploads/2023/05/p5.png)